Morphable Diffusion:
3D-Consistent Diffusion for Single-image Avatar Creation
CVPR 2024
- Xiyi Chen 1
- Marko Mihajlovic 1
- Shaofei Wang 1,2,3
- Sergey Prokudin 1,4
- Siyu Tang 1


TL;DR: We introduce a morphable diffusion model to enable consistent controllable novel view synthesis of humans from a single image. Given a single input image and a morphable mesh with a desired facial expression, our method directly generates 3D consistent and photo-realistic images from novel viewpoints, which we could use to reconstruct a coarse 3D model using off-the-shelf neural surface reconstruction methods such as NeuS2.
Overview Video
Coming Soon!Method
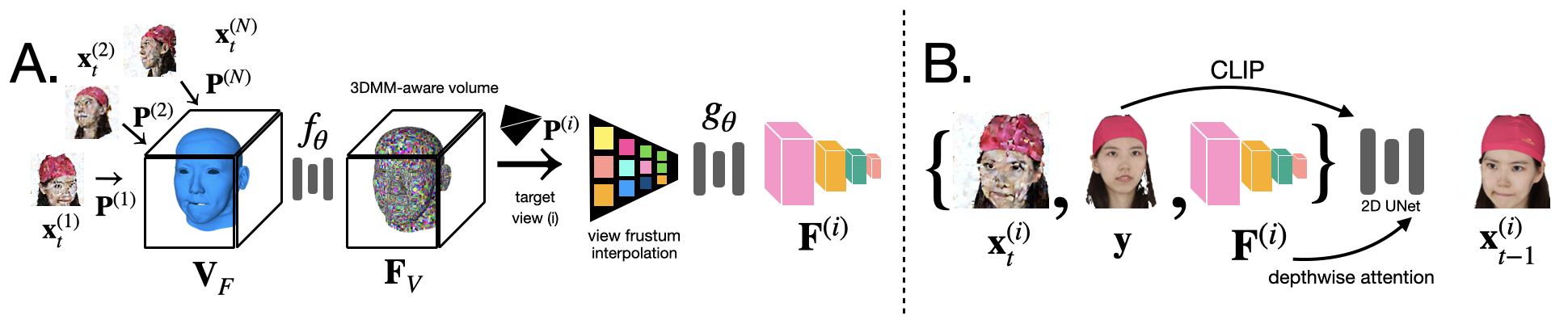
✨ Highlights:
- Unproject 2D noise features onto 3D mesh vertices with camera parameters $P^{(1:N)} = (K^{(1:N)}, R^{(1:N)}, T^{(1:N)})$.
- Process the unprojected features by a SparseConvNet $f_\theta$ to output a 3DMM-aware feature volume $\mathbf{F}_V$, which is further interpolated to the frustum $\mathbf{F}^{(i)}$ of a target view $(i)$ that we wish to synthesize.
- Denoising with 2D UNet akin to SyncDreamer with depth-wise attention.
🌟 Main Contributions:
- Proposed a multi-view consistent diffusion pipeline that conditions the generative process on a deformable 3D model for the task of animatable human avatar creation.
- Proposed a more efficient training scheme that disentangles the reconstruction (guided by the input image) and the animation (guided by the underlying morphable model)
Novel View Synthesis of Faces
We test our method for single-view reconstruction of human faces on the FaceScape dataset and compare our method with EG3D, pixelNeRF, SSDNeRF, and SyncDreamer. For EG3D, we use a custom GAN inversion repository to search for the latent code that produces the best resemblance. Our method produces the best scores on the perceptual metrics while preserving accurate facial expressions and good resemblance, which is attributed to the effective conditioning on the morphable model.
Novel Facial Expression Synthesis
We test our method for novel facial expression synthesis from single image and compare our method with MoFaNeRF. Our method produces better resemblance.
We finetune our method on 16 views of the test subject in neutral expression and compare the finetuned model with DiffusionRig. Our finetuned model improves the resemblance slightly compared to the results with single input image, and produces images with better fidelity compared to the baseline.
Novel Facial Expression Synthesis on in-the-wild Face Images
We test our method on in-the-wild face images generated by StyleGAN2. You can try our interactive viewer with individual control of view/identity/facial expression.

Identity: stylegan1

Expression: kiss
View

Novel View Synthesis of Full Bodies
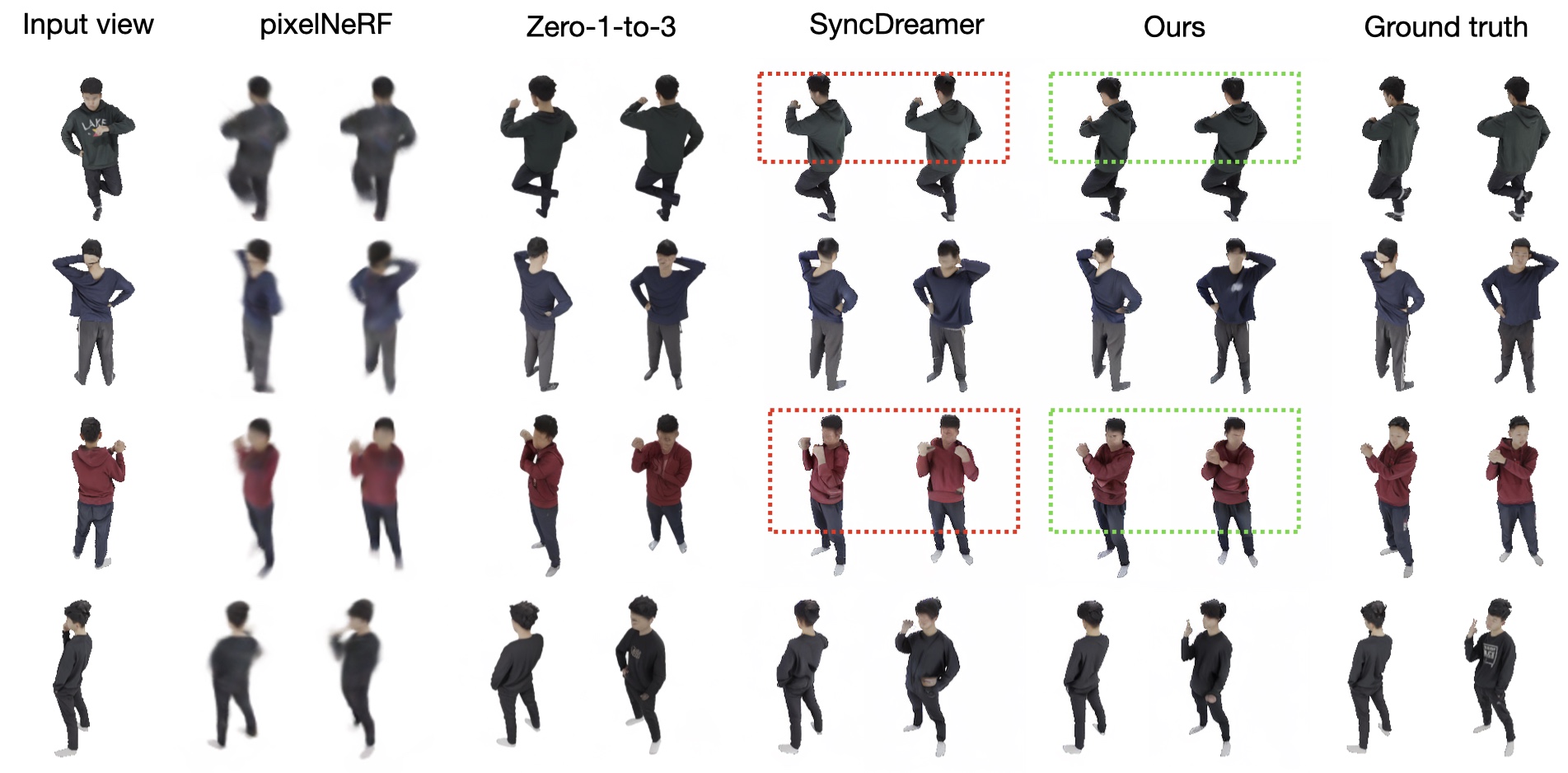
We also test our method for single-view reconstruction of human full-body images on the Thuman2.0 dataset and compare our method with pixelNeRF, zero-1-to-3, and SyncDreamer. Given a single full-body image in any pose, our method produces novel views of the person with the most accurate poses.
Full-body Animation
We also show that our method could be applied to animate a full-body image using SMPL meshes as driving signals.
Citation
@article{chen2024morphable,
title={Morphable Diffusion: 3D-Consistent Diffusion for Single-image Avatar Creation},
author={Xiyi Chen and Marko Mihajlovic and Shaofei Wang and Sergey Prokudin and Siyu Tang},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}
Acknowledgements
We thank Korrawe Karunratanakul for the discussion on per-subject finetuning of diffusion models, Timo Bolkart for the advice on fitting FLAME model, and Malte Prinzler for the help with the color-calibrated FaceScape data. This project is partially supported by the SNSF grant 200021 204840. Shaofei Wang also acknowledges support from the ERC Starting Grant LEGO-3D (850533) and the DFG EXC number 2064/1 - project number 390727645.
The website template was borrowed from Michaël Gharbi.